



Table of content

SMARTe GTM Intelligence
Start Smarter Prospecting Today
AI ready B2B data sounds like another industry buzzword. But right now, it’s quietly becoming the difference between AI that works and AI that disappoints.
Revenue teams everywhere are investing in AI outreach, automation workflows, and CRM-connected assistants. The demos look smooth. The promises sound convincing. Yet once these systems go live, things start breaking in small but costly ways. Emails land in dead inboxes. Personalization references outdated roles. Automation runs perfectly, just on the wrong data.
That’s the problem most teams don’t see at first. The AI isn’t failing. The data underneath it isn’t built for how AI operates.
Traditional B2B data was designed for humans. Sales reps could spot errors, verify contacts, and adjust as they worked. Machines don’t pause to double-check. They trust the input completely. When the data is outdated or inconsistent, AI scales those mistakes faster than any human team could.
The result is frustration. Teams wonder why real performance never looks like the demo they were sold.
The solution starts earlier than most expect. Before adding more AI tools or automation layers, revenue teams need data that is clean, structured, and reliable enough for machines to act on without constant human correction. That’s where AI ready B2B data stops being a trend and becomes a foundation.
What "AI-Ready" B2B Data Actually Means (And What It Doesn't)
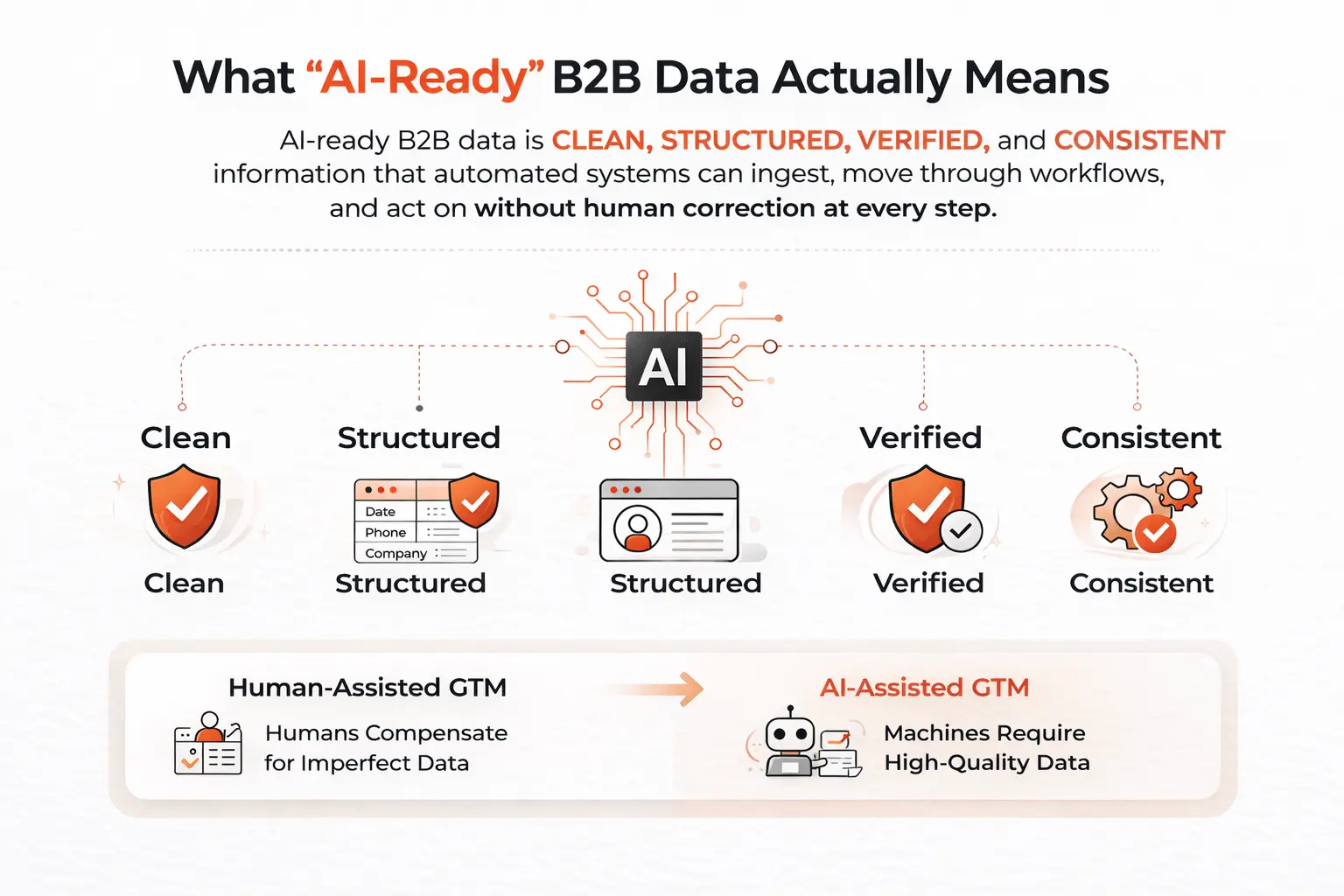
Let’s clear up a common misunderstanding first.
AI-ready does not mean data with a fancy marketing label. It is not a feature you switch on or an upgrade you add later. AI readiness is a structural quality. It describes whether your data can reliably power automated systems or whether it only works because humans keep fixing it along the way.
Here’s the simple definition.
AI-ready B2B data is clean, structured, verified, and consistently formatted data that automated systems can ingest, move through workflows, and act on without human correction at every step.
That’s it.
But the gap between this definition and the reality inside most GTM stacks is larger than many teams realize.
Take a closer look at your data at the field level. You will often find mixed formats coming from different sources, duplicate records with slightly different company names, phone numbers stored in multiple country formats, and job titles that have not been updated for months or even years. Some fields remain empty because imports failed or mappings were never fixed.
When humans review records one by one, these problems feel manageable. Reps adjust. Ops teams patch issues. Work still gets done.
AI changes that equation.
An AI agent does not pause to question inconsistent fields. It does not correct formatting errors or notice outdated context. It simply acts on whatever data it receives.
The move from human-assisted GTM to AI-assisted GTM is really a shift in tolerance for data quality. Humans compensate for imperfect data. Machines do not.
SMARTe GTM Intelligence
Start Smarter Prospecting Today
Why Your Current Data Is Probably Not AI Ready
Most RevOps teams, if they're being honest, would admit their data quality is "good enough." And for the manual era of sales and marketing, it was. But let's look at what "good enough" actually breaks when you introduce AI into the workflow.
1) Personalization at Scale Falls Apart
AI messaging tools depend on accurate and current context. They pull job titles, company details, and role information directly from your data.
If your records show someone as a Director of Marketing at a company they left over a year ago, the AI will still write a confident message based on that information. The result is not personalization. It is personalization that is clearly wrong.
Nothing damages credibility faster than outreach that feels outdated. Prospects notice immediately, and sender reputation suffers over time.
2) Automation Sequences Hit Dead Ends
Automation increases speed, but it also increases the cost of bad data.
Every incorrect record creates friction:
- Emails bounce and hurt deliverability.
- Calls go to disconnected numbers.
- Sequences waste steps on unreachable contacts.
When workflows run automatically, there is often no human checking errors before they multiply. One bad dataset can affect thousands of automated actions within days.
3) CRM Enrichment Becomes a Liability
Many teams enrich their CRM using providers that update data monthly or quarterly. That worked when reps were still verifying information manually.
But today, the CRM feeds AI workflows directly. When bad CRM data becomes your source of truth, every workflow built on top of it starts producing unreliable results.
AI needs live context, not a snapshot from three months ago.
4) AI Training and Scoring Gets Corrupted
Some teams use internal data to train lead scoring models, intent systems, or churn predictions. The quality of these outputs depends entirely on the quality of the training data.
If the inputs are incomplete or incorrect, the model learns the wrong patterns. No amount of prompt engineering or tooling can fix poor training data.
Garbage in still means garbage out.
The uncomfortable reality is that most GTM teams are trying to build a high-performance AI engine and fueling it with data that was designed for a different era.
The Four Pillars of AI-Ready B2B Data
So what does the right foundation actually look like? There are four properties that matter most when you're evaluating whether your B2B data can actually support AI-powered workflows.
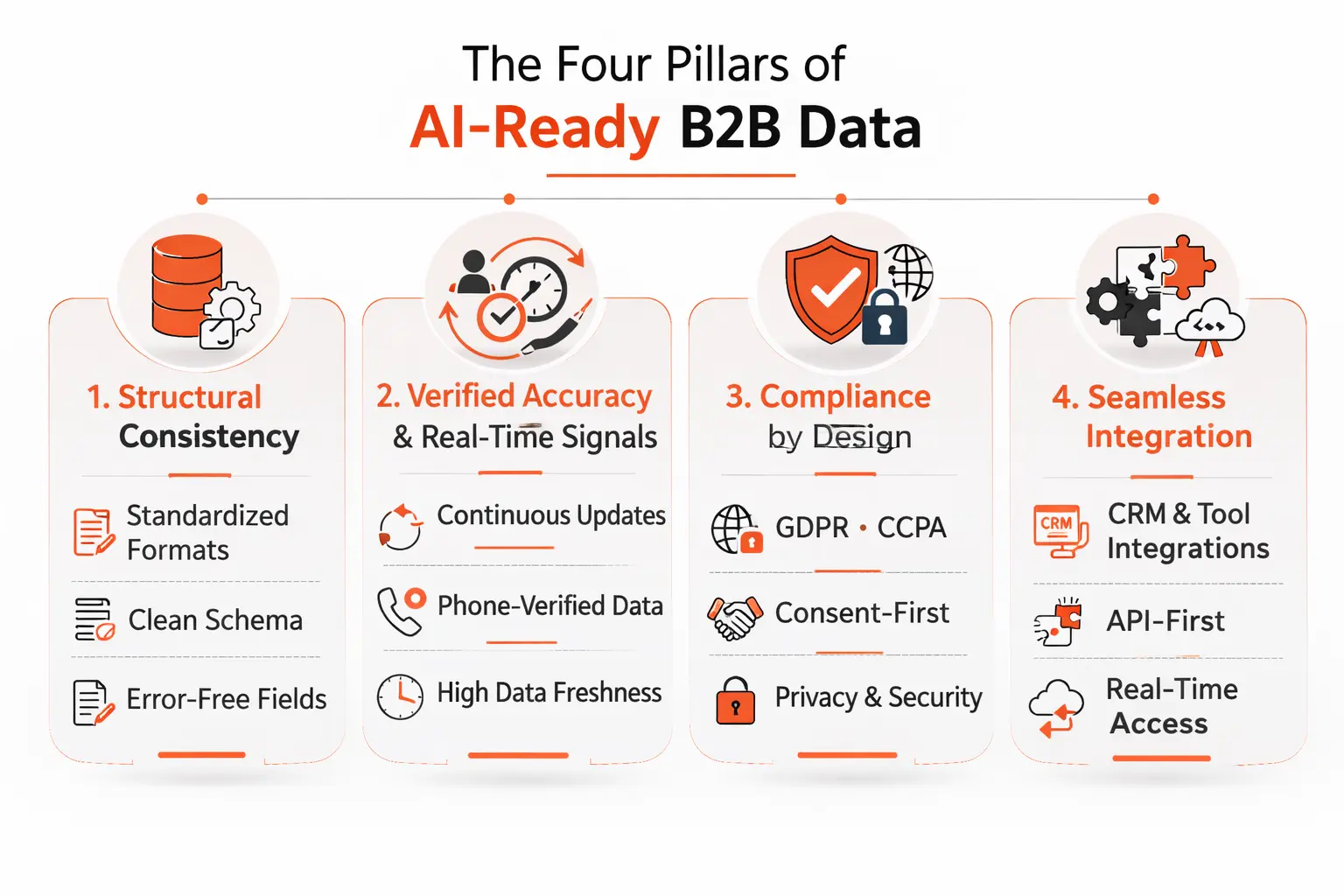
1. Structural consistency
AI systems process data in batches and make decisions based on patterns. Inconsistent field formatting — different date formats, varied phone number structures, inconsistent company name spellings — introduces noise that degrades every downstream model. Structured data means standardized, predictable schema. Every field, every record, every time.
This sounds basic. It is. But it's remarkable how many "enterprise-grade" data providers and vendors serve up fields that aren't consistently formatted across geographies, industries, or data vintages.
2. Verified accuracy with real-time signals
Accuracy at the point of collection doesn't mean accuracy six months later. B2B contact data decays fast — industry estimates put it somewhere around 25–30% per year as people change jobs, companies restructure, and roles evolve. AI-ready data needs continuous verification, not periodic batch updates.
For AI workflows specifically, phone-verified mobile numbers are a significant differentiator. Many providers offer numbers scraped from directories or aggregated from data brokers — numbers that were accurate at some point. Phone-verified means someone actually confirmed that the number connects to the right person. The difference in connect rates is significant, and for automation workflows, the difference is between a working campaign and a high-bounce disaster.
3. Compliance by design
This one tends to get treated as a legal checkbox rather than a data infrastructure concern. That's a mistake. When you're running AI-powered outreach at scale, you need to know that the data your systems are acting on is compliant with GDPR, CCPA, and the relevant regulations in each geography you're targeting.
The reason this matters for AI specifically is that automation removes the human judgment that used to serve as a soft compliance filter. A rep might naturally hesitate before cold-calling a contact in a geography where they weren't sure about consent. An automated sequence has no such hesitation. Compliant data, built with consent and privacy frameworks from the ground up, is a prerequisite — not a nice-to-have.
4. Seamless CRM and API integration
Data that has to be manually exported, cleaned, and imported into your systems before it can be used isn't really AI-ready — it's just slightly better spreadsheet data. True AI-readiness means native integration with the tools your stack runs on: Salesforce, HubSpot, Outreach, Salesloft, your enrichment layer, your sequencing platform.
And increasingly, this means API-first delivery. AI agents and workflow automation tools need to pull data dynamically, not wait for a weekly export. The data infrastructure has to be able to keep up with the speed at which AI-powered systems want to operate.
The RevOps Blind Spot: Data Infrastructure as a Revenue Problem
Here's where I want to zoom out for a second, because there's a framing issue that's holding a lot of revenue teams back.
Data quality tends to get treated as a technical problem. It lives in the RevOps backlog, gets addressed during annual data audits, and comes up when CRM hygiene starts visibly degrading. What it rarely gets treated as is a revenue problem — even though it is one, directly and measurably.
Think about it this way. Your SDR team is sending 200 emails a day. If 20% of your contact data is inaccurate — which is conservative — that's 40 wasted touchpoints a day per rep. Multiply that by your team, multiply by the quarter, and then ask yourself: how much pipeline is being lost not to poor messaging or a bad market, but to just bad data?
Now add AI to that equation. If your SDR team is now running automated sequences at 5x the volume with AI assistance, bad data doesn't cost you 40 touchpoints a day — it costs you 200. The AI is amplifying your reach, but it's also amplifying your data problems.
This is why the conversation about AI-ready B2B data needs to move from the technical backlog to the GTM strategy table. It's not a systems problem. It's a pipeline problem.
What SDR Teams Actually Experience on the Ground
Let’s bring this down from theory to reality.
A lot of conversations about data quality stay abstract. Dashboards, accuracy scores, enrichment rates. But none of that explains what actually happens during an SDR’s workday.
Here’s the real picture.
When SDRs work with outdated or poorly structured data, a large part of their day goes into verification instead of selling.
- They Google companies just to confirm a contact still works there.
- They check LinkedIn before dialing because CRM job titles are often wrong.
- They fix phone number formats before adding prospects to sequences because imports created inconsistencies.
Over time, this becomes normal. Teams start treating verification as part of the job.
But it shouldn’t be.
That isn’t sales prospecting. That’s data janitorial work.
And in a world where SDRs are expected to move faster, collaborate with AI sales tools, and focus on meaningful conversations, manual data cleanup quietly drains productivity.
Now here’s where things change.
When SDR teams get access to clean, verified, AI-ready data, the shift is immediate and noticeable.
- The time once spent double-checking records moves into real outreach.
- Reps dial with confidence because numbers are accurate.
- AI-assisted emails land better because the context reflects current roles and companies.
- Sequences run smoothly instead of breaking midway.
Something else happens too — hesitation disappears. SDRs stop second-guessing the data and start trusting their workflow.
And because accurate information flows directly into the CRM, RevOps teams aren’t constantly fixing enrichment errors or duplicate records behind the scenes.
It’s the kind of infrastructure improvement that doesn’t look dramatic at first glance.
But then connect rates rise. Workflow completion improves. Pipeline quality gets stronger.
And suddenly, the numbers tell the story that dashboards never could.
Why This Is the Right Moment to Get Serious About It
The B2B AI tooling market is moving fast. New sequencing platforms, AI SDR tools, autonomous agents for prospecting and qualification — the category is evolving in real time. Every quarter there's a new capability unlocked. And almost every one of them is bottlenecked, at the foundation, by data quality.
The teams that are going to win the next two to three years of AI-powered GTM are the ones that get their data infrastructure right now, while everyone else is focused on the top-layer tooling. The sequencing platform you use matters. The AI writing assistant matters. But neither of them can outperform the quality of the data they're working with.
There's also an increasingly sharp compliance angle here. Regulation around data privacy and AI-assisted outreach is tightening across markets. GDPR enforcement is more active. State-level privacy laws in the US are multiplying. B2B teams that are running AI-powered outreach at scale on non-compliant data aren't just taking a quality risk — they're taking a regulatory one. The window to get ahead of this is now.
SMARTe: Built for AI From the Ground Up, Not Retrofitted for It
Most B2B data platforms were built for humans — reps searching, clicking, and cleaning. Then AI arrived and everyone slapped "AI-compatible" on their marketing page without changing anything underneath.
SMARTe is different. The data architecture, verification process, signal layer, and integration model were all designed with AI-powered workflows as a core requirement from day one.
Here's what that looks like in practice:
- 290M+ verified contacts across 200+ countries — consistently structured and continuously verified, so AI systems can process records reliably without hitting bad fields or stale data.
- 75%+ mobile coverage in North America, 45–50% globally — verified numbers, not scraped ones. Your automated sequences hit live lines, not dead ends.
- 86% email deliverability — low bounce rates keep your sender reputation intact when outreach runs at scale without a human in the loop.
- 90%+ CRM match rates on bulk enrichment — with real-time validation and job change tracking running automatically in the background.
- Real-time buying signals across 59,000+ technology changes — intent data, funding events, leadership changes, and headcount growth, so your AI triggers on behavior, not static lists.
- Native integrations with Salesforce, HubSpot, Outreach, Salesloft, and MS Dynamics — plus MCP support that lets AI assistants pull live SMARTe data directly into prospecting workflows.
- SOC 2 Type II certified, GDPR aligned, CCPA compliant — compliance built into the data layer, not added after the fact.
For RevOps, it's the clean data layer that makes the rest of your AI stack actually perform. For SDRs, it's the difference between verifying contacts all day and actually selling.
See it in action. Book a demo with SMARTe →
How to Audit Your Own AI Data Readiness
Before you fix a data problem, you need to see it clearly.
Most teams feel their data isn’t perfect. But very few know how bad it actually is. And without a simple audit, AI initiatives end up solving symptoms instead of the root issue.
The good news is you don’t need a massive project to understand where you stand. A focused review can reveal almost everything you need to know.
Here’s a practical way to audit your AI data readiness.
A) Check Your Bounce Rates and Connect Rates
Start with real performance data, not assumptions.
Pull the last 90 days of outreach activity and look at two numbers:
- Email hard bounce rate
- Dial connect rate
If email hard bounces are above 3–4%, your contact accuracy is likely weak.
If dial connect rates fall below 10%, your phone data probably isn’t reliable.
AI automation amplifies these problems. Every bad record turns into repeated failed actions at scale.
B) Run a Data Freshness Test
Accuracy today does not mean accuracy tomorrow.
Take a random sample of 200–300 CRM contacts and manually compare them with LinkedIn profiles.
Ask one simple question:
Is this person still in the same role at the same company?
If fewer than 70% match, your data is aging faster than your enrichment process can keep up. That means AI workflows are operating on outdated context.
C) Audit Field Consistency
Now look beyond accuracy and focus on structure.
Scan your CRM for patterns like:
- Phone numbers stored in different formats
- Multiple versions of the same company name
- Mixed country codes
- Inconsistent date formats
- Important fields left blank after imports
Humans can work around inconsistency. Automation cannot. Structural variation is one of the biggest causes of workflow failures.
D) Identify Integration Friction
Next, map how data moves across your stack.
Ask yourself:
- Where do teams export spreadsheets manually?
- Where does data need reformatting before upload?
- Which tools require cleanup before syncing?
Every manual step is a signal that automation cannot run independently. And AI-ready systems depend on smooth, continuous data flow.
E) Listen to the People Using the Data
Finally, talk to SDRs, marketers, and RevOps managers.
Ask them:
- What slows you down daily?
- What data do you double-check before acting?
- Where do workflows break most often?
Frontline feedback often reveals issues dashboards never show.
The audit process can feel uncomfortable. It usually confirms that the data foundation is weaker than expected.
But that clarity is valuable. Once you understand the real state of your data, it becomes much easier to justify investing in infrastructure that supports where your GTM motion is actually heading, not where it used to be.
The Bottom Line
AI-powered GTM isn’t some future idea anymore. It’s already here.
Revenue teams are adopting AI because the pressure to move faster and work smarter is real. The tools exist. The use cases are proven. And the potential ROI is hard to ignore.
But there’s one piece most teams overlook.
Everything depends on the data underneath.
If the data is messy, outdated, or poorly structured, AI won’t fix the problem. It will simply scale it. Workflows break. Automation misfires. Results fall short of what the demo promised.
That’s why AI-ready B2B data isn’t just another feature upgrade. It’s a foundation decision.
Teams that recognize this — and invest in data built for machine systems, real-time workflows, and compliant automation — are the ones that actually unlock AI’s value.
Everyone else keeps asking the same question:
Why did the demo work better than real life?
If you’re building an AI-powered revenue motion and want to understand what a strong data foundation really looks like, SMARTe is worth a serious look.
Because the gap between data that works for humans and data that works for AI is real — and for many teams, it’s more expensive than they realize.






