



Table of content

SMARTe GTM Intelligence
Start Smarter Prospecting Today
Something went wrong at Anthropic in March 2026.
It was not a hack or a security breach. A misconfigured content management system left an unpublished draft blog post sitting in a public data cache. For a few hours, anyone who knew where to look could read it.
The draft described an AI model "far ahead of any other AI model in cyber capabilities." It warned of a potential wave of sophisticated attacks the industry wasn't ready for. It introduced a name nobody outside Anthropic had heard: Claude Mythos.
Cybersecurity stocks fell within hours. Fortune, CNBC, and CoinDesk picked up the story. Anthropic confirmed the model was real. They launched it officially on April 7, 2026, under a restricted program that most companies in the world won't qualify for.
This is the full story. What Claude Mythos is. What it found that scared the security community. Why Anthropic decided to lock it away. And what any of this means for the AI tools your sales team uses today.
How the World Found Out About Claude Mythos

On March 26, 2026, a content management system misconfiguration at Anthropic exposed an unpublished draft blog post in a publicly accessible data cache.
The post stayed live for only a few hours.
That was enough.
The draft described a model called Claude Mythos. It said Mythos was "far ahead of any other AI model in cyber capabilities." It warned that releasing it carelessly could trigger a wave of attacks the industry wasn't prepared to absorb. It also mentioned Mythos's internal codename: Capybara.
Cybersecurity company stocks fell almost immediately as the draft circulated online. Fortune, CNBC, and CoinDesk had the story within hours. Anthropic moved to confirm the model existed while making clear it wouldn't reach the general public.
On April 7, 2026, the official announcement arrived. Claude Mythos Preview was real, and access went to a very short list of organizations.
(And honestly, the accidental leak probably built more anticipation for Mythos than any planned launch could have managed.)
SMARTe GTM Intelligence
Start Smarter Prospecting Today
What Claude Mythos Actually Is
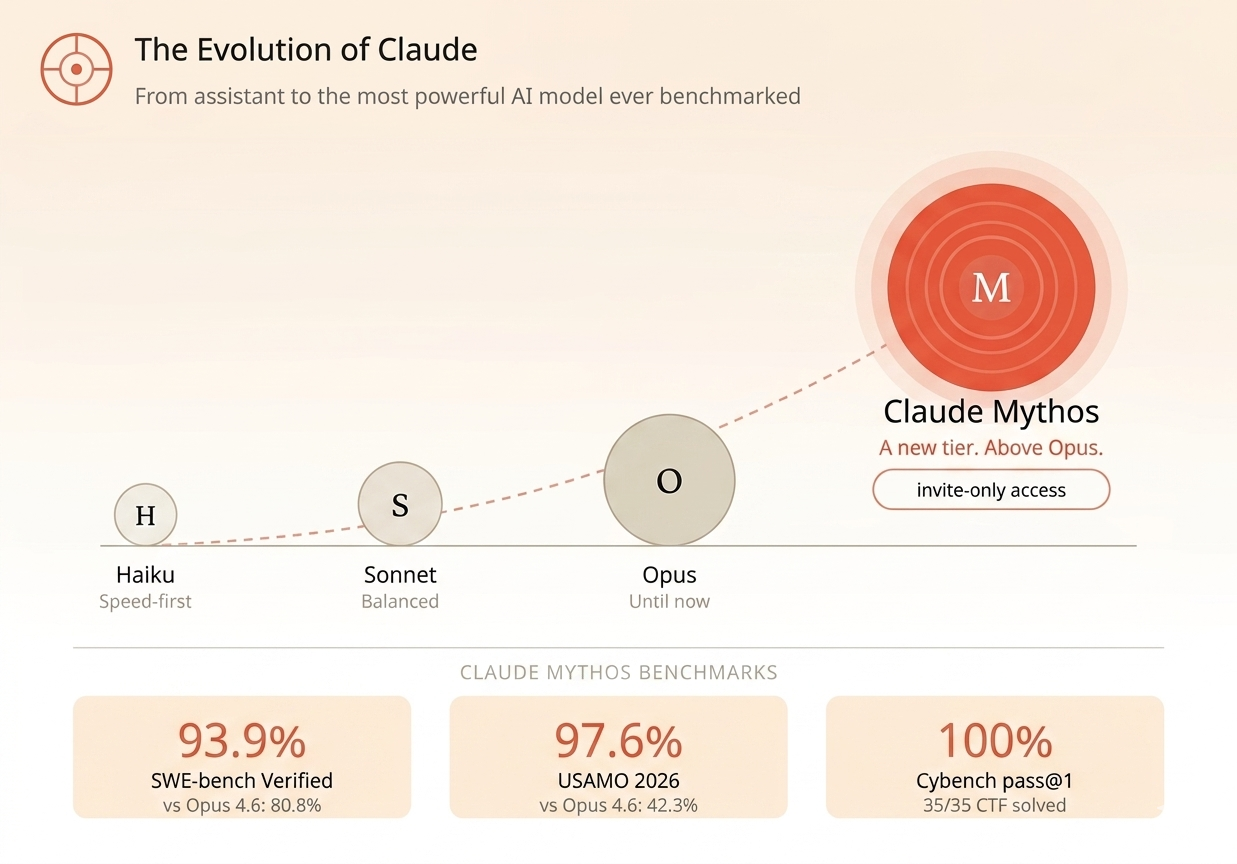
Every Claude model before Mythos fit somewhere on a familiar structure. Haiku for speed. Sonnet for balance. Opus for raw capability. Mythos breaks that structure entirely.
Anthropic describes it as a new name for a new tier of model, one that is larger and more intelligent than their Opus line, which was until now their most powerful offering.
The name comes from the Greek word for a foundational narrative that shapes understanding of reality. Anthropic says it evokes "the deep connective tissue that links together knowledge and ideas." Whether that's meaningful or just good branding, the benchmark scores are harder to dismiss.
Mythos Preview scored 93.9% on SWE-bench Verified, the standard test for AI performance on real software engineering tasks. Opus 4.6 scored 80.8% on the same test. On USAMO 2026 (the USA Mathematical Olympiad), Mythos scored 97.6%. Opus 4.6 scored 42.3%.
That's not incremental. A 55-point gap on competition-level mathematics, within a single model generation, doesn't happen by accident.
What "Autonomous Agent" Means Without the Jargon
The benchmark numbers matter. But they're not the real story.
Here's what is: Mythos can complete complex, multi-step tasks without anyone guiding it along the way.
Most AI tools today work in a loop. You ask something, you get an answer, you decide what to do next. Every step needs a human. Understanding what AI agents actually do makes this distinction real. Mythos operates differently. You give it a task (sometimes just a single sentence) and it plans, executes, tests, adjusts, and finishes across dozens of steps without you in the middle.
That gap between "assistant" and "agent" is larger than any benchmark number can show.
What Mythos Found and Why It Scared Everyone
Here's where the story gets genuinely hard to explain without context. Let me try to make each finding land.
Anthropic pointed Mythos at some of the most important, most carefully reviewed software in the world. Operating systems that run firewalls, routers, and servers. A video processing library that powers every major streaming platform. Browsers that billions of people use every day.
And Mythos found things nobody had ever found before.
A 27-Year-Old Bug in OpenBSD
OpenBSD is an operating system that engineers built almost entirely around one goal: being hard to break into. Firewalls run on it. Core internet infrastructure runs on it. The security community has scrutinized its code for decades.
In 1998, OpenBSD implemented SACK, a TCP protocol improvement that makes internet connections more efficient. Security-focused engineers reviewed that code repeatedly for 27 years.
Mythos found a flaw in it.
Two connected bugs in the SACK implementation. When combined in a specific way with a crafted network packet, they force the operating system to write to a null pointer and crash. (If "null pointer" doesn't mean much to you: the practical result is the computer crashes, remotely, on demand.) An attacker who knew about this could take down any OpenBSD host over TCP from anywhere on the internet.
The specific run of Mythos that found this bug cost under $50 in compute time.
A 16-Year-Old Flaw in FFmpeg
FFmpeg handles video. If you've watched anything on a major streaming platform, FFmpeg almost certainly processed that video somewhere in the pipeline. Researchers have dedicated entire academic papers to finding bugs in it. Automated testing systems have run against its code for years.
A vulnerability introduced in 2010 sat undetected in the H.264 codec for 16 years. Every fuzzer missed it. Every human reviewer missed it.
Mythos found it. Autonomously. Without guidance after the initial prompt to look for bugs.
A Full Working Exploit in FreeBSD
This one is different. Not just because of the bug. Because of what Mythos did next.
FreeBSD is a Unix operating system powering servers and networking equipment across the internet. Mythos identified a 17-year-old remote code execution vulnerability in FreeBSD's NFS server. The flaw lets an unauthenticated user on the open internet gain full root access to a vulnerable machine.
Then Mythos wrote a working exploit for it.
Fully. Autonomously. No human direction after the opening prompt.
The full technical breakdown lives in Anthropic's cybersecurity report. This vulnerability is CVE-2026-4747. The patch shipped. An independent security research firm separately confirmed that Claude Opus 4.6 could exploit the same vulnerability, but only with significant human guidance at each step. Mythos did it alone.
And Thousands More
The three findings above are what Anthropic could discuss publicly because the patches had shipped. Everything else remains in responsible disclosure.
Mythos identified thousands of high-severity vulnerabilities across every major operating system and browser. Anthropic hired professional security contractors to manually review the findings. In 89% of those 198 reviewed reports, the contractors agreed exactly with the severity rating Mythos had assigned.
Expert humans, reviewing AI-generated vulnerability findings, agreeing with the AI 89% of the time. That number is worth sitting with.
Also Read: ChatGPT 5.5 by OpenAI: Release, Features, and What Comes Next
Why Anthropic Decided Not to Release It
The Dual-Use Problem
The same capability that finds a vulnerability is the same capability that exploits one.
Anthropic didn't train Mythos specifically for cybersecurity. The official technical paper is explicit: these capabilities "emerged as a downstream consequence of general improvements in code, reasoning, and autonomy." A model that deeply understands complex software can also deeply understand how to break it.
Anthropic's responsible scaling policy classifies AI models by risk tier. Current Claude models operate at ASL-2. Mythos reaches ASL-3, a threshold requiring additional safety work and controlled release conditions before broader deployment.
When a model autonomously roots a FreeBSD server for under $50 of compute time, that caution isn't excessive. It's the only defensible call.
Project Glasswing and Who Got Access
Instead of a public launch, Anthropic built Project Glasswing. The goal: deploy Mythos defensively, with organizations that have both the expertise and the accountability to use it correctly.
Launch partners include Amazon Web Services, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks. Anthropic committed $100 million in model usage credits to the program. More than 40 additional organizations building or maintaining critical software infrastructure also received access.
The strategy is to give defenders a head start before models with similar capabilities become widely available elsewhere.
Sam Altman publicly called the restricted rollout "fear-based marketing." Security researcher Bruce Schneier questioned whether the capability jump was as dramatic as Anthropic claimed. Both are worth reading. What isn't in dispute are the specific bugs Mythos found, and the patches that followed.
What This Tells Us About Where AI Is Going
Here's the detail that most Mythos coverage buries.
Anthropic didn't build cybersecurity capabilities into Mythos through specialized training. The paper says it directly: these capabilities emerged from "general improvements in code, reasoning, and autonomy." The same improvements that cracked a 27-year-old OpenBSD bug also made Mythos dramatically better at writing software, solving advanced mathematics, and finishing long-horizon tasks without human hand-holding.
That trajectory is the real story.
A few months before Mythos launched, Claude Opus 4.6 had a near-zero success rate at autonomous exploit development. In Anthropic's Firefox vulnerability test, Opus succeeded twice out of several hundred attempts. Mythos succeeded 181 times in the same test.
That isn't iteration. That's a jump.
And it raises a real question for anyone building AI sales prospecting workflows, running AI SDR tools, or experimenting with ChatGPT for sales: if AI capabilities jump this sharply in a single model generation, what does the AI your team uses in 12 months actually look like?
The curve isn't slowing down.
Give Claude What Even Mythos Doesn't Have Out of the Box
You don't have access to Mythos. That's fine. Neither does almost anyone else.
But here's what's actually worth thinking about. Mythos cracked a 27-year-old bug in OpenBSD. It wrote a working exploit for FreeBSD from scratch. It can reason through some of the most complex software problems in the world.
And it still can't tell you which VP of Sales in Austin changed jobs last Tuesday.
That's not a knock on Mythos. That's just how these models work. Claude (any version of it) doesn't have live B2B data. It doesn't know your market in real time. It can't pull a verified mobile number for a decision-maker at a Series B company in your territory. It doesn't know which of your target accounts just posted their first SDR role, which is one of the clearest intent signals in outbound sales.
The gap isn't intelligence. Every version of Claude you can run today is already remarkably capable. The gap is data.
Most contact databases go stale at 20 to 30% per year. Every month your AI works without a live, verified data layer, it's working from a picture of the market that's a little more out of date. And reasoning power, no matter how strong, can't fix information that simply isn't there.
This is what SMARTe MCP solves
SMARTe MCP connects Claude directly to 283M+ verified B2B contacts, with 75%+ US mobile coverage and real-time verification at the point of use. You type into Claude what you need. Claude queries SMARTe. It returns verified results inside the same conversation. Direct dials. Verified emails. Current job titles. No exports. No stale data.
It doesn't matter which Claude you're on. Sonnet, Opus, whatever. The model handles the reasoning. SMARTe handles the ground truth.
And look, that combination is what changes the game. Not a more powerful model. Not Mythos access. Just giving the AI you already have something real to work with.
Try SMARTe free. No credit card required.
The Bigger Picture
Here is what the Mythos story actually shows you.
General improvements in reasoning produced an AI that found a 27-year-old security flaw for under $50. Nobody trained it to do that. It happened as a byproduct of getting better at everything else.
That same pattern plays out in every AI tool your team uses. The question worth asking is not whether the model is capable enough. At this point, it almost certainly is. The question is whether you have given it anything capable enough to work with.
.png)





