Oops! Something went wrong while submitting the form.
Most teams I talk to are already using Claude for something in sales. Writing emails, summarizing call notes, prepping for demos. Useful. But using Claude to actually qualify B2B leads, with live verified data feeding directly into the conversation, is a different thing entirely.
The average sales rep spends less than two hours a day actually selling. The rest goes to admin, research, and gut-call routing decisions that shouldn't require a human at all. Lead qualification is one of the biggest time sinks in that pile.
What I found is that Claude handles this well when you give it the right inputs. Structured, verified, current B2B data. Feed Claude that alongside a clear ICP and it reasons across all of it in seconds.
This is the workflow I actually use.
Why Lead Qualification Is Still Broken
The CRM Problem: Data Without Decisions
According to HubSpot's 2024 Sales Trends Report, sales reps spend only two hours per day actually selling. The rest goes to admin, research, and manual review. Lead qualification sits in that second bucket, and it eats more time than most sales managers realize.
CRMs like HubSpot and Salesforce are excellent at logging data. They are not built to interpret it. A VP of Engineering at a 250-person SaaS company shows up in your CRM with 40 fields populated. Your CRM tells you nothing about whether that person is worth your AE's attention this week.
So SDRs fill the gap manually. They research each lead, apply their own judgment, and route based on feel as much as data. The result is inconsistent, slow, and wrong often enough to hurt.
SMARTe GTM Intelligence
Start Smarter Prospecting Today
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
What Traditional Lead Scoring Gets Wrong
Points-based lead scoring treats every signal as independent. Job title match: 10 points. Company size: 8 points. Form fill: 15 points. The model doesn't understand that a CMO who downloaded a whiteboard template is completely different from a CMO whose company raised a Series B last month, added three SDR manager roles in 60 days, and has active Bombora intent signals on your category.
Both might score 72. One is worth your AE's morning. The other needs six more weeks of nurture.
The average MQL-to-SQL conversion rate across industries sits at around 13%. That means 87% of leads marketing calls "qualified" don't make it through to sales. (I think a big part of that gap comes from scoring logic that can't read context, not from bad marketing.)
What "Live B2B Data" Actually Means
Before explaining the workflow, this term needs clarification. "Live data" gets thrown around loosely, and the distinction matters for why Claude works here.
Firmographic and Technographic Context
Firmographic data covers the basics: industry, headcount, revenue tier, geography, growth stage. It tells you whether a company belongs in your ICP before any scoring happens.
Technographic data tells you what tools they use. If you sell a sales engagement platform and the account runs Outreach today, the conversation is very different from an account that still uses spreadsheets. Claude reasons differently on those two leads, and it should.
Buying Signals and Intent Data
This is where the real qualification signal lives. Buying signals like funding rounds, leadership changes, and headcount spikes tell you the timing is right, not just that the company fits.
Intent data layers on top of that. A company that fits your ICP and has active Bombora intent signals on your category is a different animal from the same company without them. Both look identical in a firmographic filter. Buying triggers like these separate a cold fit from a warm opportunity.
Why Freshness Beats Volume
A 500-field CRM record from eight months ago is worse than a 50-field record pulled today. B2B data decays fast: job changes, company pivots, tech stack swaps. Claude will reason confidently on stale data if you feed it stale data. Garbage in, garbage out applies to AI reasoning just as much as it does to spreadsheets.
The quality of your inputs decides the quality of Claude's output. Not the prompt. Not the model. The data.
My Actual Setup (Three Layers, Nothing Fancy)
The setup sounds complicated from the outside. It isn't. Three layers. Each one has a clear job.
Layer 1: The Data Sources
Two sources cover everything Claude needs:
CRM (HubSpot or Salesforce): Deal stage, activity history, contact fields, last touch. This gives Claude the relational context: where the lead is in your funnel and what's already happened.
B2B data provider: Verified contact data, firmographics, technographics, and intent signals. This is the enrichment layer that makes the CRM record actually useful. Evaluating which B2B data partner to use matters more than people think. Coverage, verification method, and freshness all determine whether Claude gets usable inputs or noise.
I also use lead enrichment to automatically fill gaps in existing records before they hit this workflow.
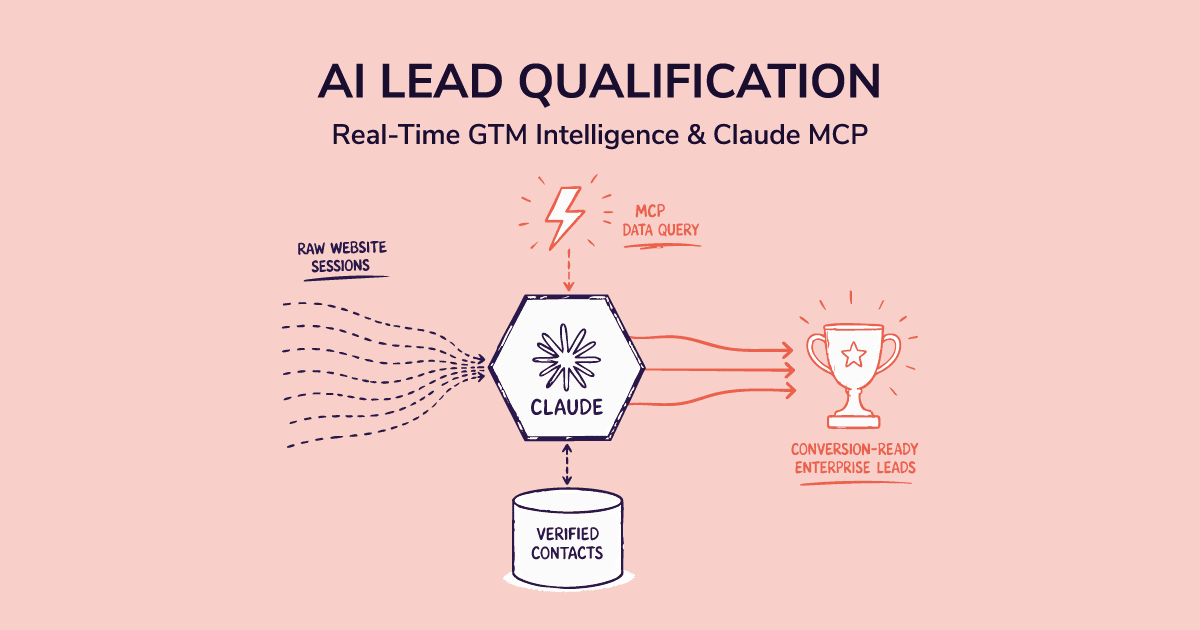
Layer 2: The Connection Layer (This Is Where Most Workflows Break)
Here's where teams hit a wall. Getting structured B2B data into Claude's context means manual exports, copy-paste into chat windows, inconsistent formatting, and sessions that don't carry context from one lead to the next. Most teams try this once, find it messy, and go back to manual qualification.
The fix is a data connection layer that pipes structured, verified contact and company data directly into Claude's context, without manual prep each time.
That's what SMARTe MCP does.
SMARTe MCP (Model Context Protocol) gives Claude real-time access to SMARTe's verified B2B database: 283M+ contacts, 66M+ company profiles, 64K+ technographic products tracked, 75%+ US mobile coverage, and Bombora intent signals built in. No exports. No formatting work. Claude pulls live, verified data directly inside the conversation.
What Claude can access once connected:
Verified contact data (email, mobile) for 283M+ decision-makers globally
Company firmographics for 66M+ companies (headcount, revenue signals, growth indicators)
Technographic data across 64K+ products
Bombora intent signals built in, no separate integration needed
Real-time verification at point of use, not a static snapshot from months ago
One honest note: SMARTe MCP solves the data prep problem. It doesn't write your ICP or build your prompt. That work still belongs to you. If you want to see how SMARTe's data connects to other AI-driven outreach workflows beyond Claude, how SMARTe powers Outreach AI covers the integration model in a different context.
For a broader look at what else is available in this space, the best MCP servers for sales teams breaks down the options across different use cases.
Layer 3: Claude as the Reasoning Engine
Claude's job here is not to write emails. Not to summarize a company's About page. Its job is to look at a structured lead record and make a prioritization call. This is different from what most people use AI for in sales. AI SDR tools handle outreach automation. Claude handles reasoning. The output is a decision, not a draft.
Given clean, structured inputs and a well-defined ICP in the system prompt, Claude identifies patterns across multiple weak signals, assigns a score, explains the reasoning, flags missing data, and recommends a next action. That output goes directly to the SDR. No interpretation required.
How I Structure Data Before Sending It to Claude
The formatting step is where most DIY attempts fail. People dump a raw CRM export into Claude and expect a thoughtful qualification decision. That's not how this works.
The Fields That Actually Move the Needle
Not every CRM field is useful. These six to eight fields are what Claude actually needs:
Industry (specific vertical, not just "technology")
Headcount (and ideally headcount growth rate over the last 90 days)
Revenue tier (if known)
Contact's job title and seniority
Tech stack (especially competitors or complementary tools)
Forty fields with half empty produces worse outputs than eight clean, current fields. Cut everything that doesn't inform a purchase decision.
What a Clean Lead Record Looks Like
A markdown table works fine for manual sessions. JSON is cleaner for API-level workflows. Here's what a single lead record looks like before it hits Claude:
Company
Acme Corp
Industry
B2B SaaS, HR Tech
Headcount
180 (up from 130 six months ago)
Revenue Tier
~$12M ARR (Series B, raised 8 months ago)
Contact
VP of Sales, 3 years in role
Tech Stack
Salesforce, Outreach, ZoomInfo
Buying Signals
Hired 3 SDR managers in 60 days; Bombora intent on "sales intelligence"
Deal Stage
New, no prior contact
Last Activity
n/a
That buying signals row is the one most teams skip. That single field often changes the entire score.
The Exact Prompt I Use (And Why It Works)
This is the section most people actually want. Here's the prompt structure I use, adapted for most B2B outbound teams:
System prompt (set once, stays constant):
System prompt — set once, stays constant
You are a B2B lead qualification analyst. Your job is to evaluate leadsagainst our Ideal Customer Profile and give a clear prioritization decision.Our ICP: — Industry: B2B SaaS in sales, HR, or fintech verticals — Company size: 50 to 500 employees — Growth signals: Series A or B, active SDR hiring, tech stack expansion — Decision makers: VP of Sales, Head of Revenue, CRO — Tier 1 requirement: active buying signals presentFor each lead record I share, return: 1. ICP Fit Score (1–10) with a one-paragraph explanation 2. The single strongest qualifying signal 3. The single most important missing data field 4. Recommended next action: [ Call Now / Sequence / Hold / Disqualify ]Do not make assumptions when data is missing. Flag it instead.
User message — one per lead
Paste your lead record here as a markdown table. Fields: Company · Industry · Headcount · Revenue tier Fields: Contact · Tech stack · Buying signals · Deal stage
Why this structure works
1
Scoring with reasoning surfaces bad data, not bad AI
If the reasoning doesn't match the score, you've found a bad input. This is how you catch data quality issues before they reach your AE.
2
One signal makes the output immediately usable
SDRs don't need a paragraph. They need to know what to open the call with. One signal, clearly stated.
3
Flagging missing fields prevents false confidence
A lead that scores 8 with no headcount data and no buying signals is not actually an 8. The prompt forces Claude to surface that gap instead of burying it.
4
ICP in the system prompt means consistent scoring forever
As your ICP evolves, edit the system prompt. Every score updates automatically. No retraining, no model changes.
For defining your ICP precisely before building this prompt, every criterion needs to be specific and testable. "Mid-market SaaS" is not a criterion. "B2B SaaS, 50 to 500 employees, Series A or B" is a criterion.
And ICP in sales context is worth reading if you're still working through what your real ICP looks like. A vague ICP in the system prompt produces vague scores, regardless of how good the lead data is.
What Claude Does Better Than Manual Scoring
I want to be direct here. Claude makes mistakes. It over-scores leads with impressive titles but no real buying signals. It occasionally misses nuance an experienced AE would catch in 30 seconds on a call. But three specific things it does better than human manual scoring or rules-based models.
Multi-Signal Pattern Recognition
Rules-based scoring treats each signal as a checkbox. Claude treats signals as a system. A company that recently switched CRMs, hired two new SDR managers, and has active intent signals on sales intelligence tools tells a story that a 74-point score does not. Outbound prospecting at any real scale means SDRs can't hand-read every signal combination for 50 leads a day. Claude can. That's the job.
Consistent Scoring Across Your Whole Team
Ask five SDRs to score the same lead. You'll get five different answers. That's not a people problem. It's a process problem. Consistent scoring criteria applied inconsistently produces inconsistent pipeline. Claude gives the same answer every time given the same inputs and the same prompt. That consistency makes pipeline generation reporting meaningful. When a lead reaches your AE, the SDR can say "Claude scored this a 9, here's the signal." That's a handoff, not a guess.
Research Speed Per Lead
Manual research on a single account takes 15 to 25 minutes for a thorough SDR. Claude processes a structured lead record in seconds. HubSpot's research confirms that AI tools are already saving sales pros two hours a day on manual tasks. Across 50 leads a day, that's several hours back. Those hours go to actual outreach. That's where AI sales prospecting tools earn their value: not by replacing the rep, but by clearing enough time for the rep to actually do their job.
One honest note on ChatGPT: it works for this workflow too. I've tested both. In my experience, Claude's structured reasoning on tabular data is slightly cleaner and the explanations are more specific. But the workflow above runs with either model.
Limitations You Should Know
This workflow has real constraints. Knowing them upfront saves you from building on a shaky foundation.
Output quality depends entirely on data freshness. If your enrichment provider serves eight-month-old records, Claude reasons on eight-month-old reality. Good B2B data isn't just about coverage. It's about how recently that coverage was verified.
Claude cannot access your CRM or external sources on its own. Without a connection layer like SMARTe MCP, this workflow requires manual data preparation before every session. That's manageable for 5 leads. It doesn't scale to 50.
High-stakes enterprise deals still need human judgment. A $200K ACV deal with six buying committee members does not get routed based on an AI score alone. I'd use Claude as a first filter here, not a final answer.
Hallucination risk when inputs are sparse. If a lead record has three fields populated out of eight, Claude will sometimes make inferences that look like findings. The "flag missing data" instruction in the prompt exists to counter this. But watch for it.
The Bigger Picture
A McKinsey report found that 67% of organizations using AI in sales and marketing saw revenue growth in the previous 12 months, often driven by faster follow-up and better lead prioritization.
The advantage in outbound is no longer who has the most data. Every team can buy a list. Every team can run a scoring model. The teams that win are the ones who reason on top of their data faster than everyone else, and act before the window closes.
CRMs gave every team the same storage. AI gives every team the same reasoning engine. The gap now is in what you feed it and how quickly you move on the output.
Owais Bagwan is a Product Marketing Manager and GTM strategist with 8+ years of experience in product marketing, go-to-market strategy, and AI-led automation. At SMARTe, he shapes product positioning and builds AI-powered systems that connect messaging to pipeline. He writes about B2B marketing, GTM strategy, and practical AI for modern revenue teams.





.png)





